I love the Wayback Machine but it has some bizarre and crippling flaws which make it incapable of preserving the web’s content. In fact, the last 5 or 6 times I went to recover old content via the Wayback Machine, the Internet Archive had lost all of the content that it had already saved at one point.
This can happen 2 ways. I already wrote about one of them: Wayback Machine Error: Page cannot be displayed due to robots.txt. The other way is when a website is 301 Redirected.
How this happens
Wayback Machine may save a site’s content for years, even after a site goes offline or is shut down. But, then, if the site is later redirected to a new site, Wayback somehow magically “loses” all of the old content. I wonder if the content is still there on their servers but just inaccessible from the web interface. Hmm…
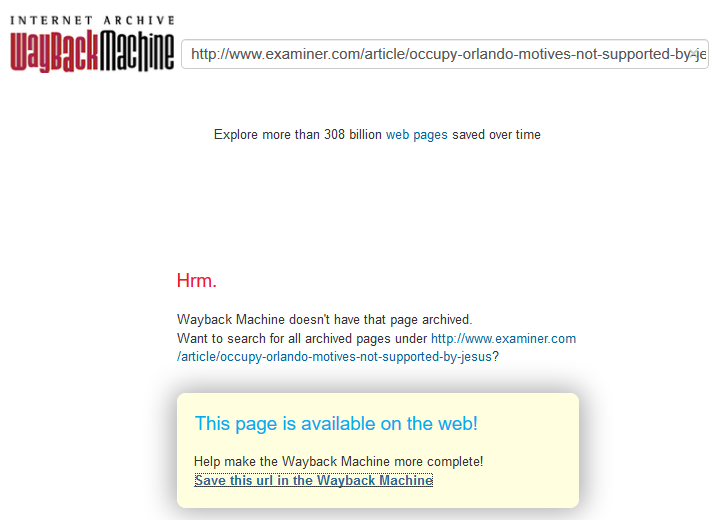
Screenshot of a wayback page that wasn’t indexed. This isn’t a great example, but even it WAS indexed, Wayback would (incorrectly) say “This page is available on the Web!”
This is an example of some old, deleted Examiner.com content. So in this case, I went ahead and clicked on “Save this URL in the Wayback Machine” even though the URL was NOT on the web. I just wanted to see what would happen. And what happened is exactly what happens any time a site is 301 redirected.
Wayback changed the URL to AXS.com.
So the old, original article is now lost, which was about “Occupy Orlando” and now just point to the AXS.com home page:

This is bizarre.
I looked and was unable to find anyone at the Internet Archive to reach out to. I’d like to make them aware of this problem. It must be a mistake! Isn’t the entire point of the Internet Archive to … you know … archive the Internet?
Did you lose content from the Wayback Machine?
It happens over and over with everything from small sites to larger publishers which go away. In 2016 Examiner.com shut down and in more recent history, the Internet lost LAist.com, SFist.com and DCist.com. Hundreds of thousands of pages which the Internet Archive DID have saved are coming up missing all the time due to this “flaw”.
I can’t imagine it was designed to work this way.
If you lost your content or know a solution to this problem please comment below. I have hundreds of people who will thank you for it who reached out to me when Examiner.com closed.
- Google “Pure Spam” Penalty Deindexes Sites March 6 2024 - March 12, 2024
- What Happened to ChicagoNow.com? - August 30, 2022
- The December 2021 Google Local Pack Algorithm Update - December 17, 2021

I realize this is an oldish post, but I stumbled across it and find it confusing. You’re saying you tried to save a page in the Wayback Machine that was already gone, and you didn’t understand why it saved the redirect instead of the already deleted article? If so, uh… you can’t really archive something that doesn’t exist anymore…
Unless your actual point was that the Wayback Machine used to have the article saved but the archived version was gone when you looked for it later. That would be a genuine anomaly. Which unfortunately seems to happen, albeit uncommonly.
>Unless your actual point was that the Wayback Machine used to have the article saved but the archived version was gone when you looked for it later. That would be a genuine anomaly. Which unfortunately seems to happen, albeit uncommonly.
I am finding that is occurs at an alarming rate, and in a systematic way for certain sites. Streaming sites belonging to major media corporations which serve up region-locked content over various range-restricted ccTLDs as an example. Do you have any idea why these redirects might be incorporated by the wayback machine? Or could you possibly point me to some further discussion on this subject? Thank you
I have been looking for a way to find a copy of a 301 with no luck. If I found this page It would be worth a chunk of change. Just seems everything I have tried does not work. I am about to pull my hair out. Well what is left anyway. The 301 is only a couple months old. I am not that great with computers, that could be the problem. I want to pay someone for their time with a nice bonus if they find what I need. No one seems to know how to find things on the wayback. As soon as I say wayback machine it’s a “I don’t know anything about that.” I had even put a 10K reward for anyone that can find this information. Got some people interested, but that’s about it. I tried to hire a hacker on the dark web. Just don’t know if they are real or rip off. The Information is public and not personal. What I need is the date I was in a store, that’s it. I am about sick thinking about this money slipping away. All I need is just one person that knows about this kinda thing.
Long time later. You ever find this stuff?
I found the same thing. I needed some info. that was redirected 301. Now i don’t know where to go. I should never donated any money to the wayback. If anyone can remove things at will, and put in redirects to something to hide what was there, what good is the wayback.
I found the same thing. I needed some info. that was redirected 301. Now i don’t know where to go. I should never donated any money to the wayback. If anyone can remove things at will, and put in redirects to hide what was there, what good is the wayback. Save all that info just to let it be hidden. I am a bit pissed off. The donation they ask for is crap. They need to tell people they will get a 301 redirect and the wayback has no real use.
Problem still exists in 2024 I’m afraid. I set up a page on my own web server, and another page to 301-redirect to the first page. I then tried to save the 301 redirect URL in the Wayback Machine. It saved the page it was redirecting to (which is fair enough), but it did not also save the 301 redirect page itself, which means if somebody types that 301-redirect URL into the Wayback Machine, it won’t even take them to the page it redirected to, it just says not saved and do you want to save it. In my case that matters because the 301-redirect URL is to go into the printed version number of a piece of software, and if my site ever goes down, I still want people to be able to look up the website being referred to by this software in case it’s needed for historical reasons or something. (I’m putting the redirect URL into the “website” field of this comment in case that’s useful to anyone.) In previous years I seem to remember that redirects were treated like 404s: they were simply saved as a version of the page, and you could still see the previous and following versions or you could choose to follow the redirect if you like.
Hey, I thought I experienced the same issue but now it appears to be working and showing the original website before the redirect. Still not sure if it was the browser or URL or what. But try this one:
https://web.archive.org