If you are attempting to recover content off of a deleted domain or an old website, the Wayback Machine can be a lifesaving resource.
And other times it can be extremely frustrating.
Error: Page cannot be displayed due to robots.txt.
Sometimes a website displays just fine one day, then you go back to the Internet Archive’s “Wayback Machine” to get the content and it is gone. This is a very common scenario since digging through the archive is a very slow, time consuming process.
People often ask:
- My old site has always worked but lately it says “Page cannot be displayed due to robots.txt.”
- Weeks ago I bookmarked the site I’m interested in, and somehow I cannot display it anymore.
- Why can’t I see my site on the web archive?
- The Wayback Machine has a problem and is broken, when will they fix it?
Here’s what the error message looks like which makes people’s hearts sink:
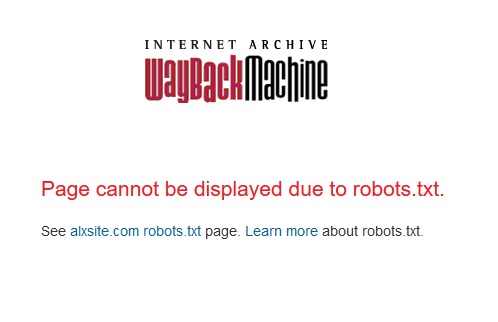
Screenshot of the error message “Page cannot be displayed due to robots.txt”
Why does this error appear?
This error appears when the current site has blocked crawlers from crawling the site. A command in the domain’s robots.txt file blocks crawlers. The command looks like this:
Disallow: /
In rare cases some webmasters block the Wayback Machine’s spiders exclusively via this code:
User-agent:ia_archiver
Disallow: /
The problem:
The problem you, I, and almost everyone reading this article have is this:
Even if the content has been on the Internet Archive for 15 years, if a site, for any reason, suddenly has a robots.txt which blocks crawlers, all of the archived content on the Wayback Machine suddenly becomes inaccessible.
This is very irritating because Wayback Machine has neglected to assist people with this for over a decade now and has, as far as I know, no policy or explanation on their website. Threads in their forum go back to 2006 with people trying to figure out what the flaw is.
Apparently, this is by design.
It adds salt to many people’s wounds who already lost their content once, were overjoyed to have found it, and then lost it a second time – this time – permanently.
To further frustrate people: I do believe the content is sitting on the Internet Archive’s servers.
How to solve this:
If you’re reading this, you have likely lost access to the website. IF you do have access to the website, fix your robots.txt file to allow spiders to crawl it, and ta-da, Wayback Machine will once again display your old content.
If you do not have access to the site’s robots.txt or the site has been 301 redirected, you’re out of luck.
Tell the world about about it:
Did Wayback Machine block you from old content you were trying to reach?
How do you feel about this?
- Google “Pure Spam” Penalty Deindexes Sites March 6 2024 - March 12, 2024
- What Happened to ChicagoNow.com? - August 30, 2022
- The December 2021 Google Local Pack Algorithm Update - December 17, 2021
I wish it were this easy. I replaced my default robots.txt file with:
User-agent: *
Allow: /
and I still cannot get into the archives. Ugh.
So I should have mentioned this above, but once changing the robots.txt file, you will have to wait until the Wayback spiders hit it again and discover crawling is allowed. I just experimented with this a couple of weeks ago, and I had to wait a good 4-5 weeks.
I am not certain how often their spiders try to crawl certain sites but I suspect it varies drastically from site to site.
An alternative is archive.is.
If you page was crawled and you just updated the robots.txt file, the content will come back eventually!
Good article explained every problem i was facing with web archive, keep up the good work. cheers!