I can’t mention which site here but recently I wanted to archive a website. Unfortunately, it had 3 – 4 million pages of content. To be honest, I haven’t added it up yet, but there is well over 3.
HTTRACK
My normal site copier of choice is HTTRACK. I discovered the limitations of this program and many others though. Even after several tweaks and allocating just the right amount of RAM to it, etc, downloading an entire site consisting of millions of pages via HTTRACK just isn’t going to happen. HTTRACK can go off of a list of URLs if you can manage to crawl the site.
Breaking up the content into manageable chunks
Over here I wrote about how to crawl a site with over 1 million URLs. In a nutshell, I configured a virtual machine in Google’s cloud – basically, a supercomputer running Ubuntu – and ran screaming frog with special parameters to get me chunks of 500,000 URLs at a time.
I exported the URL list as a CSV file, then save the CSV as a TXT, edited the TXT and stripped the commas and quotes out, then resaved as a TXT file which I could feed to HTTRACK via the command line.
Running HTTRACK via the command line is a real nail biter as you can’t see what it is doing. But you can check the output of a destination folder in a new window to see if it is doing something. 🙂
I killed the Windows version – after 99,999 URLs it just “gives up”! lol
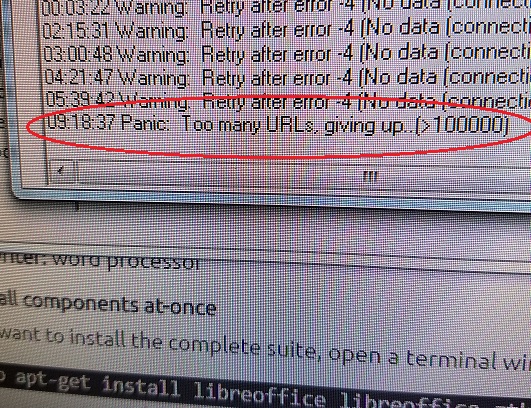
When your software tells you that it has given up.
Multitasking
Thanks to the supercomputing power I had at my fingertips, I took a total of 9 or 10 TXT files and set up my virtual machine to run HTTRACK in 10 different command shells.
In this case the target website did not ban me from having too many ‘threads’ running (too many connections). In this particular case I was able to grab around 250,000 pages of content in 36hrs or so. That’s 6,944 pages per hour or 115 pages per minute. And that’s in EACH instance. I could be off on thse numbers as once I finally got everything up and running I logged out of my virtual machine for a few days.
Later, I took all the folders, combined them together and skipped any misc duplicates and ta-da, I now have a folder with millions of pages of content.
Is there an easier way?
I don’t know. A single site map would have made my life drastically easier. But pulling a sitemap for a website you do not have access to is tricky. Large sites like this have hundreds or even thousands of sitemaps and the darn things are GZ compressed.
If you know of an easier way to copy a few million pages of content please fill me in.
I should also note that my time was limited. The site I was playing with was getting ready to shut down so I wanted to work as quickly as possible.
- Google “Pure Spam” Penalty Deindexes Sites March 6 2024 - March 12, 2024
- What Happened to ChicagoNow.com? - August 30, 2022
- The December 2021 Google Local Pack Algorithm Update - December 17, 2021

In the windows version in Tab Limits, Maximum number of links to as high as you need. And you can download all. Httrack warns for a high limit, because it will take some memory but now that is is not a problem with the computers of today I think. There is also a commandline options, but I do not use that so I can not help with that.